Day 8 Inference – Estimability, degrees of freedom, hypothesis tests, contrasts
8.1 Announcements
- Highlight questions from Assignment 3:
- Why are degrees of freedom not always integer numbers?
- What is the difference between sums of squares?
- What is the best size of blocks when designing an experiment?
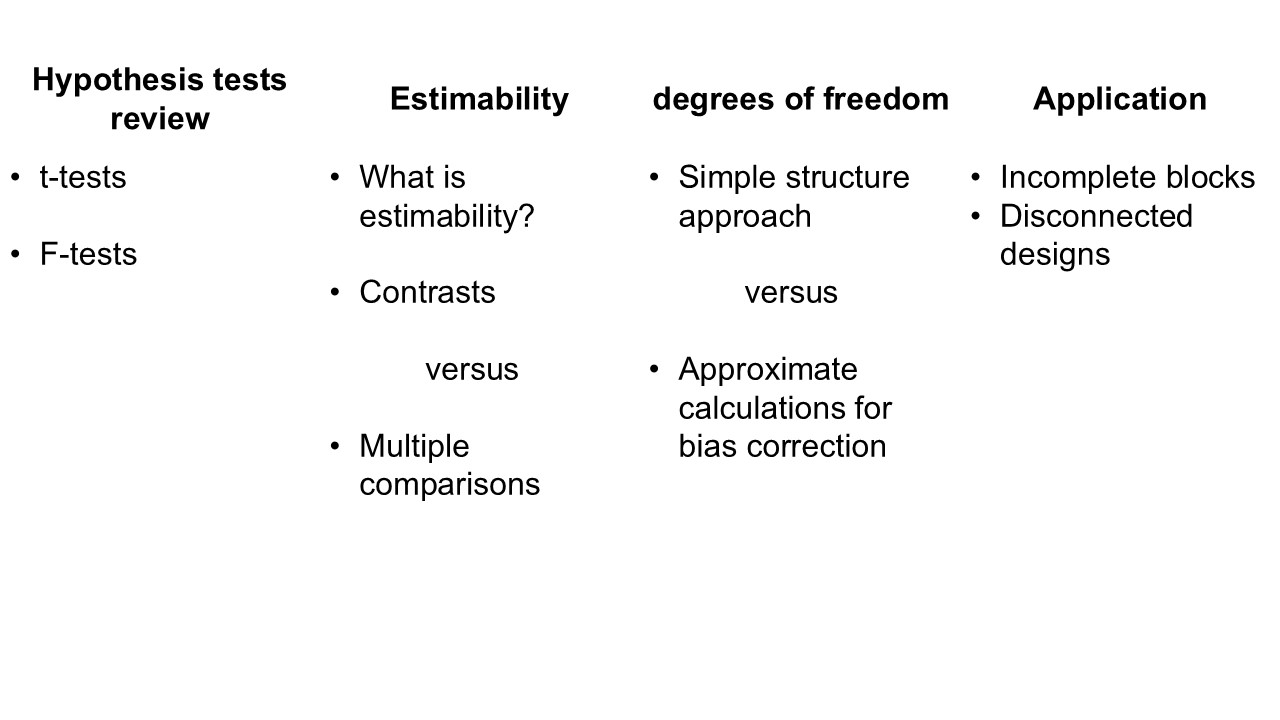
Figure 8.1: Overview of today’s class.
8.2 Review: Hypothesis tests, t-tests, F tests
8.2.1 Hypothesis tests
- Classic statistics have been deeply associated to falsifiability in the advancement of Science.
- Hugely influenced by Karl Popper, the advancement of Science can be understood as a string of hypotheses that are constantly evaluated.
- In statistics, hypothesis tests evaluate whether a given statistic (i.e., a function of the data) is too extreme for the null hypothesis to be true.
- Normally, the null hypothesis is business as usual, and we want to evaluate if we just made a scientific discovery, or if there’s not enough evidence to say that there’s something different going on.
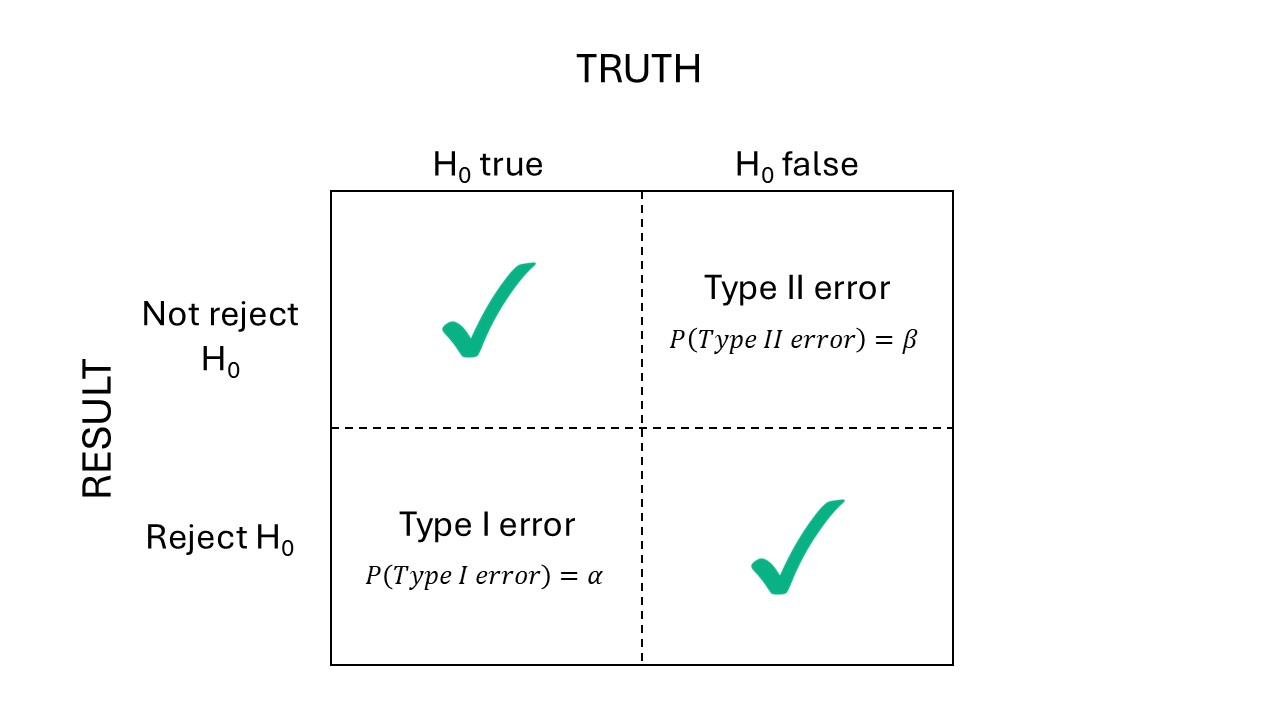
Figure 8.2: Types of errors in hypothesis tests.
8.2.2 On p-values
- The p value is the probability of observing the [t/F] statistic under the null hypothesis.
- Often, we assume \(\alpha = 0.05\), and reject \(H_0\) if \(p<\alpha\).
- ASA’s statement on p-values
- Scientists rise up against statistical significance
- Discussion
- Counterargument: In defense of p-values
- Gelman “Let us have the serenity to embrace the variation that we cannot reduce, the courage to reduce the variation we cannot embrace, and the wisdom to distinguish one from the other.” [see talk]
8.2.3 t-tests
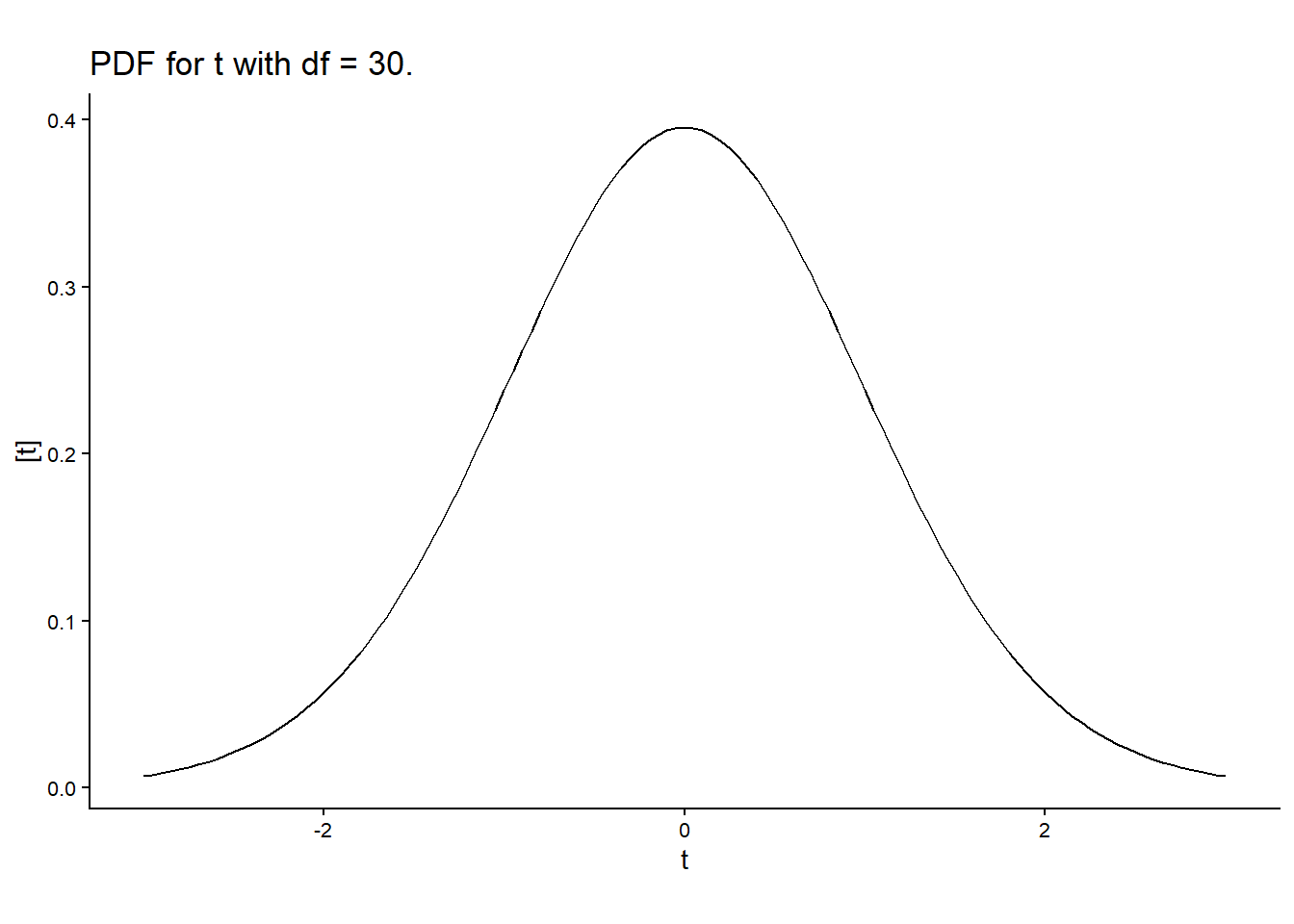
- Usually used to test whether one value/parameter/linear combination of parameters is different to a certain number.
- Steps:
- Define the target quantity \(\theta\). For example, \(\theta = \beta_1-\beta_2\).
- After observing the data, estimate \(\hat{\boldsymbol\beta}\) and \(se(\hat{\boldsymbol\beta})\).
- Calculate the test \(t\) statistic as \(t^\star = \frac{\hat\theta}{se(\hat\theta)}\).
- Compare \(t^{\star}\) to \(t_{1-\frac{\alpha}{2}, dfe}\).
- Why \(t\) distribution? \(N\) for known se, \(t\) for \(\hat{se}\).
- Note that \(t^\star\) depends on:
- sample size (\(dfe\))
- experiment design (other df)
- the variability \(\sigma^2\) associated to that system.
- Note that \(t_{crit}\) depends on \(dfe\).
8.2.4 F-tests are multivariate t-tests
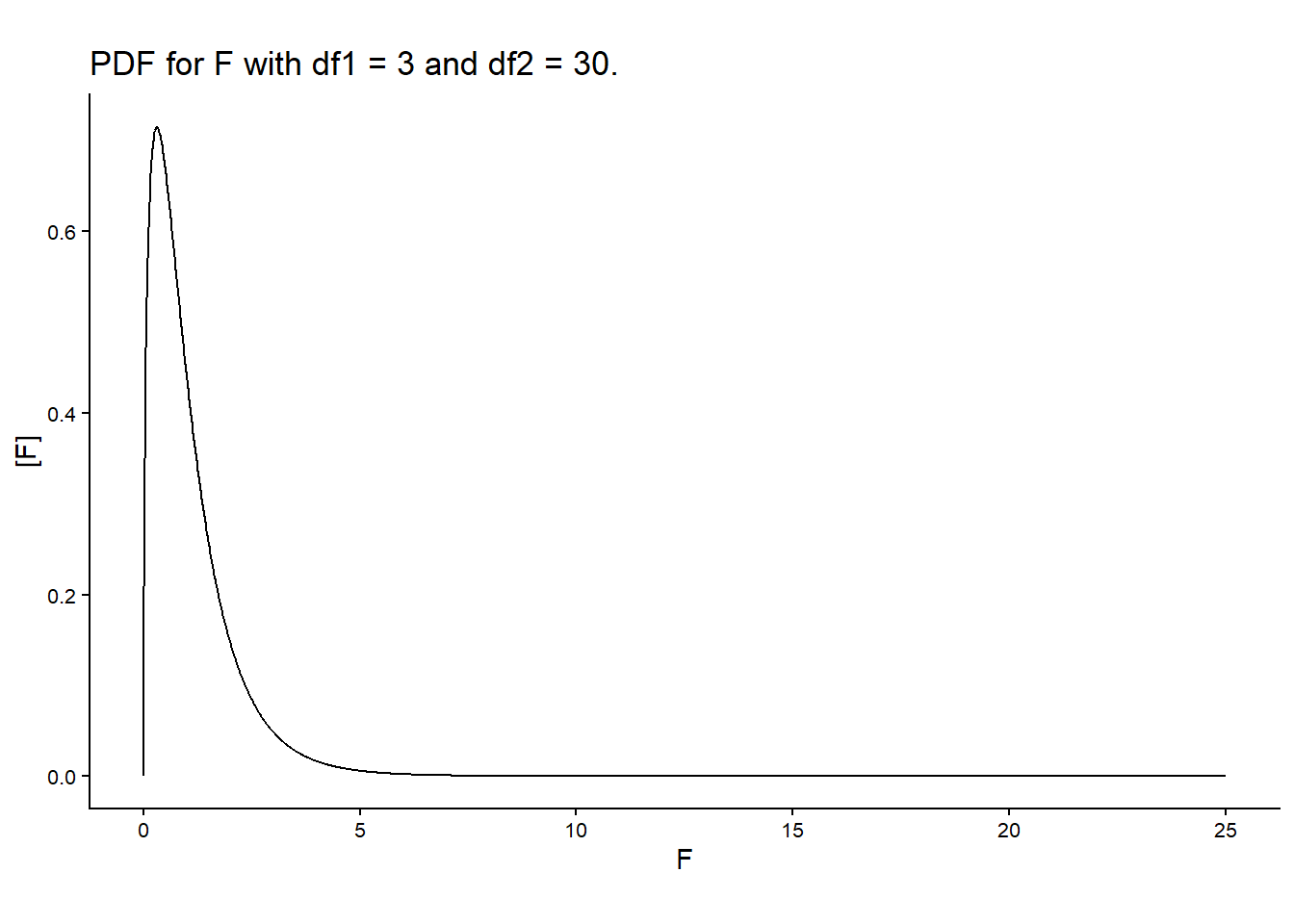
- Test the relevance of multiple factors at once.
- Consistent with the “bins” concept of ANOVA.
- Usually used to test whether a group of factor is relevant to explain variability in the data.
- Why \(F\) distribution? Ratio between two independent \(\chi^2\) distributions divided by their df.
- Steps:
- Calculate Mean Squared Errors for the different sources of variability \(= \frac{SSH}{df}\).
- Calculate the F statistic as the ratio between mean squares, \(=\frac{MSH}{MSE}\).
- Compute \(P(F>F^\star)\), using the degrees of freedom of both mean squares, df of the numerator and df of the denominator.
- Note, again, the relationship between the p value and sample size and \(\sigma^2\).
- Note, again, that the \(P(F>F^\star)\) depends on the df of the denominator.
8.3 Applied example
From Milliken and Johnson (2009).
A baker wanted to determine the effect that the amount of fat in a recipe of cookie dough would have on the texture of the cookie. She also wanted to determine if the temperature (°F) at which the cookies were baked would have an influence on the texture of the surface. The texture of the cookie is measured by determining the amount of force (g) required to penetrate the cookie surface.
Experimentation:
The process she used was to make a batch of cookie dough for each of the four recipes every day, and baked them one by one in the oven in different batches. She carried this process out each of four days when she baked cookies at three different temperatures.
library(tidyverse)
library(lme4)
library(emmeans)
df <- read.csv("../data/cookies.csv")
df$Temperature <- as.factor(df$Temperature)
df$fat_perc <- as.factor(df$fat_perc)
df$Day <- as.factor(df$Day)
df %>%
ggplot(aes(Temperature, force))+
theme_classic()+
scale_fill_manual(values = c("#DCD6F7", "#B4869F", "#985F6F", "#4E4C67"))+
labs(x = "Temperature (°F)", fill = "Fat (%)", y = "Force (g)")+
theme(aspect.ratio = .5)+
geom_boxplot(aes(group = paste(Temperature, fat_perc),
fill = factor(fat_perc)))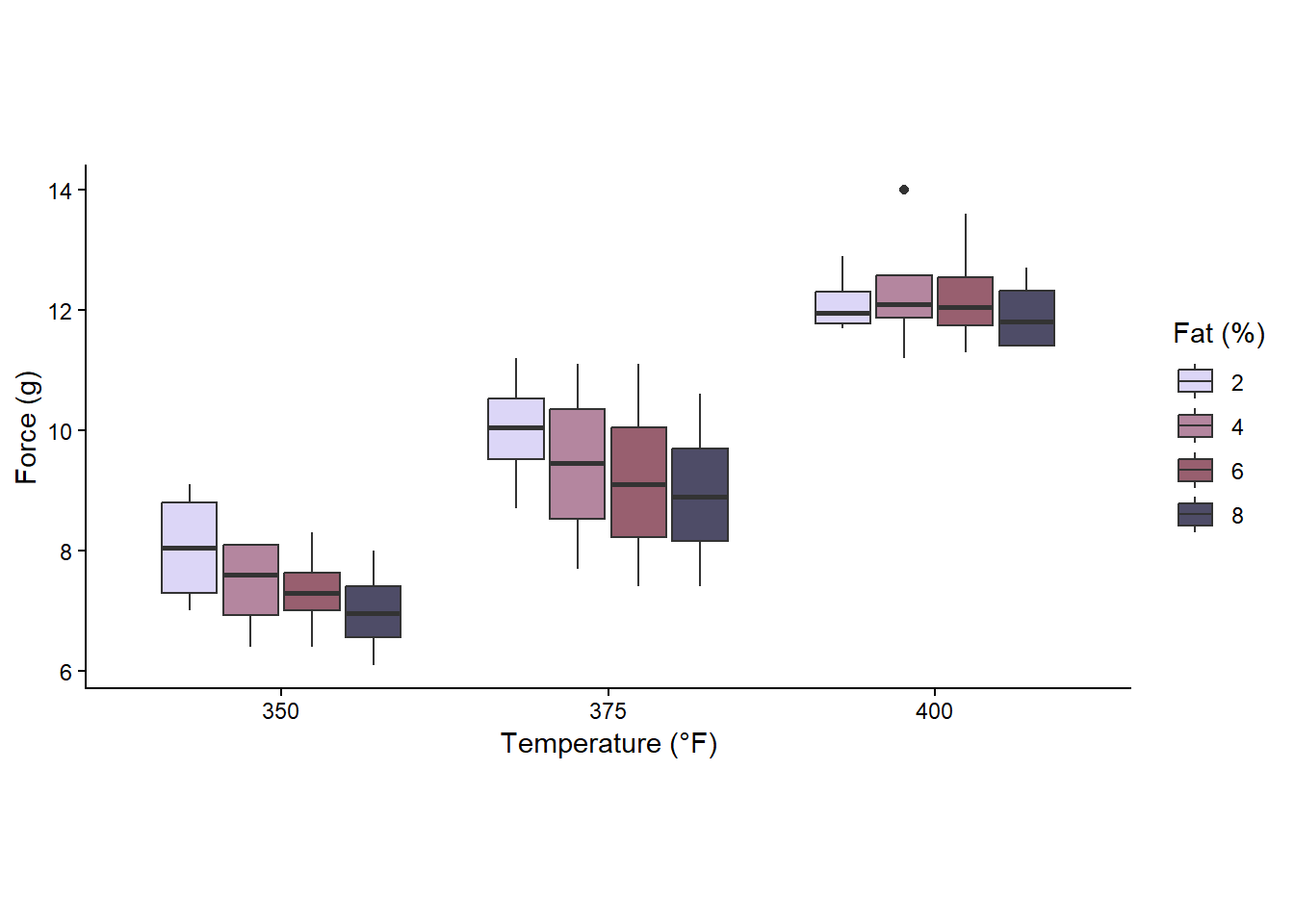
ANOVA table for cookie RCBD
| Source | df |
|---|---|
| Block | \(r-1 = 3\) |
| Temp | \(t-1 = 2\) |
| Fat | \(f-1 = 3\) |
| \(T \times F\) | \((t-1)(f-1) = 6\) |
| Error | \(N-tf-(r-1) = 33\) |
The corresponding model is \[y_{ijk} = \mu + T_i + F_j + TF_{ij} + d_k + \varepsilon_{ijk} , \\ d_k \sim N(0, \sigma^2_d), \\ \varepsilon_{ijk} \sim N(0, \sigma^2_\varepsilon), \]
and can be fitted to the data with the following R code:
The degrees of freedom for the denominator are straightforward.
8.3.1 t-test
- Objective: compare treatment means between 375 degrees temperature and 4% fat and 400 degrees temperature and 4% fat.
- Remember \(t^\star = \frac{\hat\theta}{se(\hat\theta)}\)
- \(\hat\theta = \mu_{22} - \mu_{32}\)
- \(se(\hat\theta) = \sqrt{\frac{2 \sigma^2_\varepsilon}{r}}\)
R code to get t statistics by hand
d <- data.frame(Temperature = as.factor(c(375, 400)),
fat_perc = factor(4))
hat.mu <- predict(m, newdata = d, re.form = NA)
hat.theta <- hat.mu[2]-hat.mu[1]hat.sigma2 <- sigma(m)^2
hat.sigma2_b <- as.data.frame(VarCorr(m))[1,4]
reps <- n_distinct(df$Day)
se.hat.theta <- sqrt((2* hat.sigma2)/reps)## contrast estimate SE df t.ratio
## c(0, 0, 0, 0, -1, 1, 0, 0, 0, 0, 0, 0) 2.92 0.633 33 4.621
## p.value
## <0.0001
##
## Degrees-of-freedom method: kenward-roger## 2
## 2.925## [1] 0.6330342## 2
## 4.620603## 2
## 8.202921e-058.3.2 F-test
- Objective: find out if temperature, in general, affects the texture of the cookie.
- \(H_0:\) all temperatures have the same effect on texture.
- \(H_a:\) at least one temperature has a different effect on texture.
- \(F^\star = \frac{MS_{Temp}}{MS_{resid}}\)
- \(F_{critical} = F_{1-\alpha, df_{numerator}, df_{denominator}}\)
R code to get F statistics by hand
# create models that account for different sources of variability
m.full <- lmer(force ~ 1 + Temperature*fat_perc + (1|Day), data = df)
m.TF <- lmer(force ~ 1 + Temperature + fat_perc + (1|Day), data = df)
m.T <- lmer(force ~ 1 + Temperature + (1|Day), data = df)
m.F <- lmer(force ~ 1 + fat_perc + (1|Day), data = df)
m.n <- lmer(force ~ 1 + (1|Day), data = df)
# SS II residual
sum(resid(m.full)^2)## [1] 26.84223## [1] 1.505## [1] 3.665## [1] 179.5317## [1] 1.998401e-15## [1] 0.2264496## [1] 0.92563228.4 Estimability
- A quantity is estimable if it is possible to find a linear combination of the data that provides an unbiased and unique estimate of that quantity.
- For matrix models, linear estimable functions of \(\boldsymbol\beta\) take on the form of linear combinations of the parameter vector such as \(a'\boldsymbol\beta\) where a is a \(p\times1\) vector of constants. A linear function \(a'\boldsymbol\beta\) is estimable if and only if there exists a vector \(r\) such that \(a = \mathbf{X}'\mathbf{X}r\). Each function \(x_i'\boldsymbol\beta\) is estimable where \(x_i\) is the \(i\)th row of \(\mathbf{X}\).
8.4.1 Contrasts
- Linear combinations of parameters.
- Often connected to hypothesis tests where \(H_0: \mathbf{K}\boldsymbol\beta = 0\).
- We specify the matrix \(\mathbf{K}\) that combines elements in \(\hat{\boldsymbol\beta}\).
- For example, if \(\mathbf{K} = \begin{bmatrix} 1 & -1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & -1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \end{bmatrix}\), we are estimating the contrast between [2%Fat, 350°F] and [2%Fat, 375°F] (row 1), and [4%Fat, 375°F] and [4%Fat, 400°F].
emmeansalso gives us some SE, a t value and p value associated to a hypothesis test: \(H_0:\) each row =0.
emmeans(m, ~Temperature:fat_perc, contr = list(c( 1, -1, rep(0, 10)),
c(0, 0, 0, 0, -1, 1, rep(0, 6))))## $emmeans
## Temperature fat_perc emmean SE df lower.CL upper.CL
## 350 2 8.05 0.534 18.2 6.93 9.17
## 375 2 10.00 0.534 18.2 8.88 11.12
## 400 2 12.12 0.534 18.2 11.00 13.25
## 350 4 7.42 0.534 18.2 6.30 8.55
## 375 4 9.43 0.534 18.2 8.30 10.55
## 400 4 12.35 0.534 18.2 11.23 13.47
## 350 6 7.33 0.534 18.2 6.20 8.45
## 375 6 9.18 0.534 18.2 8.05 10.30
## 400 6 12.25 0.534 18.2 11.13 13.37
## 350 8 7.00 0.534 18.2 5.88 8.12
## 375 8 8.95 0.534 18.2 7.83 10.07
## 400 8 11.93 0.534 18.2 10.80 13.05
##
## Degrees-of-freedom method: kenward-roger
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio
## c(1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) -1.95 0.633 33 -3.080
## c(0, 0, 0, 0, -1, 1, 0, 0, 0, 0, 0, 0) 2.92 0.633 33 4.621
## p.value
## 0.0041
## <0.0001
##
## Degrees-of-freedom method: kenward-roger8.4.2 Adjusting degrees of freedom for mixed models
From Assignment 3:
In class we learned that degrees of freedom represent the number of independent pieces of information. In the ANOVA tables these appear as whole numbers, but when we run mixed models in R I sometimes see fractional values (for example, 27.4). Why do mixed models produce non-integer degrees of freedom, and could you also provide a simpler or more intuitive way to think about what degrees of freedom really mean?
Answer: According to my understanding, in ANOVA, degrees of freedom come directly from how many observations are available and how many parameters are estimated, which gives whole numbers. Mixed models include both random and fixed effects and the structure of data involves often correlations among the observations for example: repeated measures on the same subject or split-plot designs). In this case, the information available to estimate parameters is not clearly separated as ANOVA. So, degrees of freedom in mixed models represent an effective amount of independent information, this might be the reason they can be fractional.
- Contrasts for balanced & complete designs have straightforward calculation of degrees of freedom.
- For unbalanced designs, incomplete blocks, missing data, and cases with more complex variance-covariance structure, the ANOVA shell does not give us exact degrees of freedom.
- Downward bias of the variance of an estimable function, leading to:
- too narrow confidence intervals
- inflated type I error rates
- Bias adjustment methods estimate the approximate degrees of freedom, which might be a non-integer number.
Satterthwaite approximation
Let \(\frac{X^2_{num}/\nu_1}{X_2^\star/\nu^\star_2}\) be the ratio of interest, where \(X_{num}^2 \sim \chi^2_{\nu_1}\) and \(X_2^\star\) is a linear combination of chi-square random variables all independent of \(X_{num}^2\), then \(X_2^\star \sim\) approximately \(\chi^2_{\nu^\star_2}\), where
\[\nu_2^\star \equiv \frac{(\sum_m c_m X_m^2)^2}{\sum_m\frac{(c_m X_m^2)}{df_m}}.\]
Kenward-Roger approximation
- Paper
- Based on REML
- Focused on \((\mathbf{X}^T\mathbf{V}^{-1} \mathbf{X})^{-1}\) (the variance of \(\hat{\boldsymbol\beta}\))
- Again, expept for variance-component-only LMMs with balanced data and their compound symmetry marginal model equivalents, the estimated covariance of \(\beta \mathbf{K}\) will tend to be underestimated.
- KR somewhat more conservative and reliable than Satterthwaite (source).
- Integrated in most statistical software.
R implementation
emmeansuses Kenward-Roger by default. [see vignette]- Everything is more tricky in GLMMs (
dfisInfin most applications).
8.5 Applied example II
From Milliken and Johnson (2009).
A baker wanted to determine the effect that the amount of fat in a recipe of cookie dough would have on the texture of the cookie. She also wanted to determine if the temperature (°F) at which the cookies were baked would have an influence on the texture of the surface. The texture of the cookie is measured by determining the amount of force (g) required to penetrate the cookie surface.
Experimentation:
The process she used was to make a batch of cookie dough for each of the four recipes every day, and baked one cookie from each recipe in the oven together. She carried this process out each of four days when she baked cookies at three different temperatures.
| Source | df | EMS |
|---|---|---|
| Block | \(r-1 = 3\) | \[\sigma^2_{\varepsilon}+f\sigma^2_w+tf\sigma^2_d\] |
| Temperature | \(t-1\) = 2 | \[\sigma^2_{\varepsilon}+f\sigma^2_w+\phi^2(\alpha)\] |
| Error(oven) | \((r-1)(t-1) = 6\) | \[\sigma^2_{\varepsilon}+f\sigma^2_w\] |
| Fat (%) | \(f-1 = 3\) | \[\sigma^2_{\varepsilon}+\phi^2(\gamma)\] |
| \(T \times F\) | \((t-1)(f-1) = 6\) | \[\sigma^2_{\varepsilon}+\phi^2(\alpha \gamma)\] |
| Error(split plot) | \(t(r-1)(f-1) = 27\) | \[\sigma^2_{\varepsilon}\] |
The corresponding model is \[y_{ijk} = \mu + T_i + F_j + TF_{ij} + d_k + w_{i(k)} + \varepsilon_{ijk} , \\ d_k \sim N(0, \sigma^2_d), \\ w_{i(k)} \sim N(0, \sigma^2_w), \\ \varepsilon_{ijk} \sim N(0, \sigma^2_\varepsilon), \]
and can be fitted to the data with the following R code:
The degrees of freedom for the denominator are not so straightforward anymore.
## $emmeans
## Temperature fat_perc emmean SE df lower.CL upper.CL
## 350 2 8.05 0.534 10 6.86 9.24
## 375 2 10.00 0.534 10 8.81 11.19
## 400 2 12.12 0.534 10 10.93 13.32
## 350 4 7.42 0.534 10 6.23 8.62
## 375 4 9.43 0.534 10 8.23 10.62
## 400 4 12.35 0.534 10 11.16 13.54
## 350 6 7.33 0.534 10 6.13 8.52
## 375 6 9.18 0.534 10 7.98 10.37
## 400 6 12.25 0.534 10 11.06 13.44
## 350 8 7.00 0.534 10 5.81 8.19
## 375 8 8.95 0.534 10 7.76 10.14
## 400 8 11.93 0.534 10 10.73 13.12
##
## Degrees-of-freedom method: kenward-roger
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio
## c(1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0) -1.95 0.731 6.79 -2.667
## p.value
## 0.0331
##
## Degrees-of-freedom method: kenward-roger